<< Back to Senior Design Course
Syllabus
Statistical Testing
Introduction
Statistical testing is
performed to determine how confident one can be in reaching conclusions from a
data set. It is highly important in
biological experiments because these often lead to data sets with wide
variability.
A population is a group under study.
For example if you are interested in comparing men to women, men would
be one population and women would be another.
There are several types of
statistical testing. The test chosen
depends on the hypothesis you are testing.
For example, the student’s T test is
used to determine whether, on average, the mean value of some variable of interest (e.g. height, age,
temperature) in one population is different from the mean value of the same
variable in another. For example,
examine the question “On average, are men taller than women?” Here the variable of interest is height, the
populations are men and women, and the statistic
of interest is the average height.
Each statistical test yields
a p value (short for probability
value) that represents the probability that the null hypothesis is correct.
The null hypothesis is generally the opposite of what you are trying to
prove. For example, you could formulate
the hypothesis that Biomedical Engineers perform better on the FE exam than
Industrial Engineers. The null hypothesis
is:
Biomedical Engineers do not
perform better on the FE exam than Industrial Engineers.
![]() Exercise 1:
Identify the population, the variable of interest and the statistic of interest
implied by the above null hypothesis.
Exercise 1:
Identify the population, the variable of interest and the statistic of interest
implied by the above null hypothesis.
If you do a T-test and
obtain a p value of 0.05, it means that:
“Given the standard
deviation of these data and the number of data points, there is a 5%
probability that we would obtain a difference in the means this large or larger
if the performance of Biomedical and Industrial Engineers were exactly the
same.”
In other words, given this
data set, we have only a 1 in 20 chance of being wrong if we claim that
Biomedical Engineers perform better on the FE exam than Industrial Engineers.
Be careful in interpreting
statistical tests. The natural thing to
think is that if your p-value is less than the designated value (in biological
applications this is usually taken as 0.05) then your hypothesis is true. Some dangers are:
1.
If you do enough
statistical tests on something, the odds are that the t-test will show
significance on something even though significance is not there. For example, if p=0.05 is taken as the cutoff
point, then 1 time out of 20 you will get significance when the underlying
distributions are the same. Thus, if you
perform 20 t-tests, odds are that one of them will show significance even though
no significance exists.
2.
If the p value exceeds
0.05, it does not prove the null
hypothesis. Indeed you can never
prove the null hypothesis. If your
hypothesis is that Burmese cats weigh more than Siamese cats and you find no
significance (p > 0.05), it does not prove that Burmese cats and Siamese
cats weigh the same. It only means that
there is not enough evidence in your data set to state with confidence that
they have different weights.
Some Often-Used Statistical Tests
Chi-Squared Test
This is used to test the
hypothesis that the data you are working with fits a given distribution. For example, if you want to determine whether
the times of occurrence of meteorites during the Leonid meteor shower are inconsistent
with a Poisson distribution, you could formulate the null hypothesis that the
arrival times follow such distribution and test whether the data contradict
this null hypothesis.
A Chi-Squared test is
typically the first test you would like to perform on your data because the
underlying probability distribution determines how you will perform the
statistical tests. Note, however, that
you cannot prove that the data follow a given distribution. You can only show that there is a strong
probability that the data do not follow the distribution.
F-test
You choose two cases of
something and formulate the hypothesis that the variances of the variable of
interest for populations are different.
For example, assume that you have two tools to measure height and you
want to know if one leads to more consistent results than the other. You could collect repeated measurements of
some item from both of these tools and then apply an F-test. (The two populations in this case are 1.
measurements taken with the first tool and 2. measurements taken with the
second tool). Note that in the T-test it
matters whether the variances of your two data sets are different. Therefore, it is a good idea to perform an
F-test on your data before you perform a T-test.
T-test
This test is probably the
most widely known of all the statistical tests.
You choose two populations and formulate the hypothesis that they are
different. For example, if you would
like to know if Altase (a blood pressure
medicine) reduces blood pressure, you could form the hypothesis that “People
who are given Altase (population 1) will have lower blood pressure than people
who are given a placebo (population 2).
Linear Regression and Pearson’s Correlation
Coefficient
Another hypothesis might be
that one variable is correlated with another.
For example, “Blood pressure is correlated with the number of cigarettes
smoked per day.” In this case you would
do a linear regression of the blood pressure vs number of cigarettes smoked and
examine the p-value for this regression.
This test is different from the T-test in that you are looking at a
functional relationship between two quantitative values rather than a
difference in means between two cases.
The p value depends on the r value (which is Pearson’s Correlation
Coefficient) for goodness of fit of the regression and the number of data
points used in the regression. When you
perform a least squares fit in Excel, one of the parameters that the software
provides in the output is the p value.
Anova
The Anova examines the
variance within each population and compares this to the variance between
populations. The simplest case is where
there are three populations, and you wish to determine whether some statistic
varies from population to population. If
you were interested in determining whether FE exam scores differed for
Biomedical Engineering, Industrial Engineering and Mechanical Engineering
students, this would be the test to use.
It can also be used for cases where you do not expect a linear
correlation but do expect some effect of a given variable. Weight, for example generally increases as
one ages, but then typically diminishes in old age. The trend is not linear, but it certainly
exists. For example, look at the
variability of blood pressure as a function of age. The categories are obtained by dividing the
subjects into specific age groups, such as 20-30, 30-40, 40-50, 50-60, 60-70,
and 70-80 years old.
More details of each
statistical test are provided later in this document.
Probability Distributions
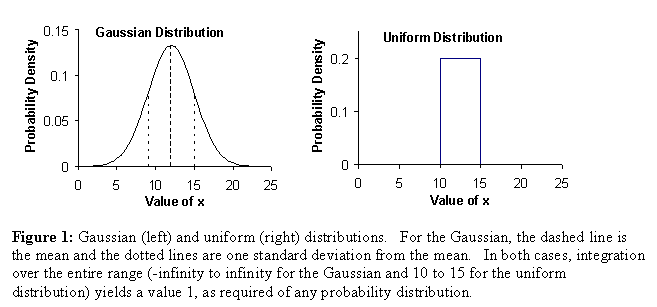 We denote the probability distribution of a random
number by f(x). F-Tests and T-Tests
assume that the probability distribution of the noise in the data follows a
Gaussian (or normal) distribution,
We denote the probability distribution of a random
number by f(x). F-Tests and T-Tests
assume that the probability distribution of the noise in the data follows a
Gaussian (or normal) distribution, 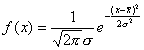 . The rand() function
in Excel generates a uniformly distributed random variable between 0 and
1. This means that the number is just as
likely to fall between 0.2 and 0.3 as it is to fall between 0.3 and 0.4, or
between 0.9 and 1. The Gaussian
distribution and uniform distribution are shown in Figure 1. The area under both curves must equal 1,
which means that it is assured that the value of a given experiment will be
somewhere in the possible range. For
example, if the experiment is the roll of a die, the result must be one of 1,
2, 3, 4, 5, or 6. Hence, the probability
of the result being 1, 2, 3, 4, 5, or 6 is 1.
. The rand() function
in Excel generates a uniformly distributed random variable between 0 and
1. This means that the number is just as
likely to fall between 0.2 and 0.3 as it is to fall between 0.3 and 0.4, or
between 0.9 and 1. The Gaussian
distribution and uniform distribution are shown in Figure 1. The area under both curves must equal 1,
which means that it is assured that the value of a given experiment will be
somewhere in the possible range. For
example, if the experiment is the roll of a die, the result must be one of 1,
2, 3, 4, 5, or 6. Hence, the probability
of the result being 1, 2, 3, 4, 5, or 6 is 1.
The Gaussian distribution is
important because many distributions are (at least approximately)
Gaussian. The “central limit theorem”
states if one takes the average of n samples from a population, regardless of
the underlying distribution of the population, and if n is sufficiently large,
the distribution of this mean will be approximately Gaussian with a mean equal
to the mean of the original distribution, and a standard deviation of
approximately: ![]() .
.
![]()
Example 1: Show that when a new random variable is
defined as “the sum of the values when a die is thrown three times,” the
probability distribution begins to take on the shape of a Gaussian
distribution.
Solution: First look at the probabilities for the sum of two dice. Anyone who has played Monopoly is aware that 2 or 12 occur with low probability, whereas a 7 is the most likely number to be thrown. Table 1 demonstrates all possible combinations of Throw 1 and Throw 2. Note that there is one way to obtain a “2,” 2 ways to obtain a “3,” 3 ways to obtain a “4,” 4 ways to obtain a “5,” 5 ways to obtain a “6,” 6 ways to obtain a “7,” 5 ways to obtain an “8,” 4 ways to obtain a “9,” 3 ways to obtain a “10,” 2 ways to obtain an “11,” and 1 way to obtain a “12.”
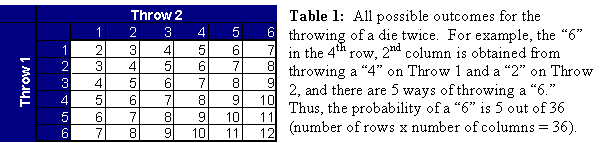
It follows that the
distribution for 2 rolls of a die is trianglular in shape. Table 2 builds on this result. On the left of the table are the possible
outcomes for Throw 3, and at the top of the table are the possible outcomes for
the combination of throws 1 and 2. At
the bottom of the table, the row marked “Frequencies” shows the frequency for
each outcome. For example, the 6 at the bottom
indicates that there are 6 different ways to obtain 7 from the roll of 2 dice.
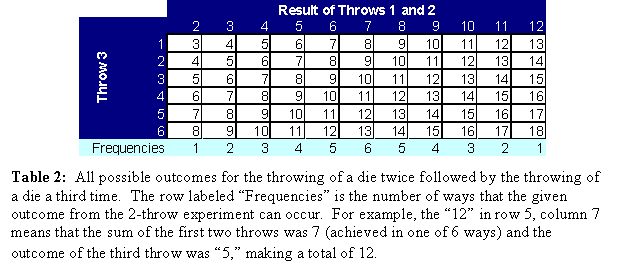 To obtain the number of combinations for each
possible result, it is necessary to multiply the number of times a given number
occurs in each column by the frequency for that column and then sum over all
columns. For example, the number of
possible 8’s 1+2+3+4+5+6 = 21. The total
number of possible combinations is 63 = 216, so the odds of
obtaining an 8 are 21/216. Table 3 shows
all combinations that can occur for 3 throws of a die and the number of times
they can occur.
To obtain the number of combinations for each
possible result, it is necessary to multiply the number of times a given number
occurs in each column by the frequency for that column and then sum over all
columns. For example, the number of
possible 8’s 1+2+3+4+5+6 = 21. The total
number of possible combinations is 63 = 216, so the odds of
obtaining an 8 are 21/216. Table 3 shows
all combinations that can occur for 3 throws of a die and the number of times
they can occur.
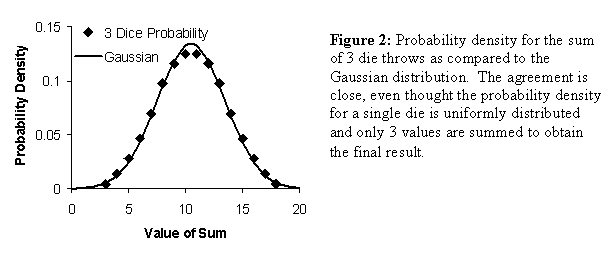
The probability density for the 3 rolls of a die are obtained by taking the frequency values in Table 3 and dividing by the total possible number of combinations (256). These values are plotted in Figure 2 along with the probability density for the Gaussian. Even when the number of values in the sum is as small as 3, close agreement is found with a Gaussian distribution.

![]()
![]() Exercise 2:
Define a random number as the number of times a coin comes up heads when tossed
20 times. For example, if the outcome is
T, T, T, H, T, H, H, H, T, H, T, H, T, H, H, H, T, T, T, T, there are 9 heads
and 11 tails, so the random number’s value is 9. This is the same as defining H as 1 and T as
zero and defining a new random variable as the sum results from all 20
tosses. Find the probability density
function for this new random variable and compare it directly to a Gaussian
distribution. (Hint: for 1 toss the
probability density is 0.5 at 0 and 0.5 at 1.
For 2 tosses, there is one way to obtain a value of 0 (two tails), two
ways to obtain a value of 1 (H, T and T, H) and 1 way to obtain a value of 2
(two heads). The density is 0.25 at 0
and 2 and 0.5 at 1. For 3 tosses, there
is a 50% chance of all values remaining the same (the 3rd toss is
tails) and a 50% chance of them increasing by 1. Thus, the possibilities are given by Table 4:
Exercise 2:
Define a random number as the number of times a coin comes up heads when tossed
20 times. For example, if the outcome is
T, T, T, H, T, H, H, H, T, H, T, H, T, H, H, H, T, T, T, T, there are 9 heads
and 11 tails, so the random number’s value is 9. This is the same as defining H as 1 and T as
zero and defining a new random variable as the sum results from all 20
tosses. Find the probability density
function for this new random variable and compare it directly to a Gaussian
distribution. (Hint: for 1 toss the
probability density is 0.5 at 0 and 0.5 at 1.
For 2 tosses, there is one way to obtain a value of 0 (two tails), two
ways to obtain a value of 1 (H, T and T, H) and 1 way to obtain a value of 2
(two heads). The density is 0.25 at 0
and 2 and 0.5 at 1. For 3 tosses, there
is a 50% chance of all values remaining the same (the 3rd toss is
tails) and a 50% chance of them increasing by 1. Thus, the possibilities are given by Table 4:
|
New Value |
0 |
1 |
2 |
3 |
|
Ways of obtaining if 3rd toss is Tails |
1 |
2 |
1 |
|
|
Ways of obtaining if 3rd toss is Heads |
|
1 |
2 |
1 |
|
Total Possible Ways of Obtaining New Value |
1 |
3 |
3 |
1 |
This table can be continued as in Table 5. One takes the probability distribution from
the previous toss, shifts it to the right and sums. This pattern is easy to implement in Excel. The astute student will notice that the
process is equivalent to convolving each successive probability distribution
with the probability distribution for a single coin. The pattern is not unexpected. In general, when forming a new random number
as the sum of random numbers from two distributions, the probability density of
the new random number is the convolution of the distributions from the two
original distributions.


![]() Exercise 3:
Show that the convolution of a Gaussian distribution with itself is Gaussian
and that therefore that a random number formed as the sum of two Gaussian
random numbers is still Gaussian.
Exercise 3:
Show that the convolution of a Gaussian distribution with itself is Gaussian
and that therefore that a random number formed as the sum of two Gaussian
random numbers is still Gaussian.
![]()
The Chi Squared Test
It is important to know the
distribution of the data you are looking at because the statistical tests
assume a specific distribution, and if your data do not follow that
distribution, the test will be invalid.
For the Chi-Squared test,
the probability distribution is divided into a set of bins and the number of
expected numbers in each bin is determined.
For example, if the distribution is uniform from 0 to 5, one can divide
it into 5 bins (0 to 1, 1 to 2, 2 to 3, 3 to 4, and 4 to 5). If 60 random numbers are obtained in the data
set, then it is expected that, on average, one should obtain 60/5, or 12 data
points per bin. One then examines the
data to determine how many points do occur in each bin and forms the statistic:
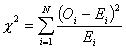 ,
,
Where ![]() is the observed number
of values in bin i and
is the observed number
of values in bin i and![]() is the expected number of values in bin i. One then compares this
Chi-Squared statistic to a table of significance.
is the expected number of values in bin i. One then compares this
Chi-Squared statistic to a table of significance.
![]()
Example 2: Use a Chi-Squared test on the set of data in Table 6 to determine whether it is consistent with a Gaussian distribution with a mean of 2 and standard deviation of 1.


Solution:
First, the bins will be defined. One
would like to have few enough bins that at least five data values fall in each
bin. Since there are 50 data points
above, there must be less than 10 bins.
The following bins will be used: 1. Less than -1 (8 values), 2. From -1
to 0 (8 values), 3. From 0 to 1 (10 values), 4. From 1 to 2 (14 values), 5.
From 2 to 4 (5 values), 6. Above 4 (5
values).
One can obtain the expected
number of values that fall within each bin by looking at the following
integrals.
![]() ,
,
where ![]() is the Gaussian
probability distribution. For example,
to find the number of values that should fall between 2 and 3 one must
calculate:
is the Gaussian
probability distribution. For example,
to find the number of values that should fall between 2 and 3 one must
calculate:
![]() ,
,
or more specifically,
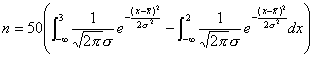 .
.
Tables are available for ![]() for a mean of 0 and
standard deviation of 1. Therefore, we need to express our bin limits in terms
of the number of standard deviations from the mean. These values are shown in Table 7, along with
the values of
for a mean of 0 and
standard deviation of 1. Therefore, we need to express our bin limits in terms
of the number of standard deviations from the mean. These values are shown in Table 7, along with
the values of ![]() .
.
|
Bin Uppler Limit Value |
-1 |
0 |
1 |
2 |
4 |
|
|
Std. Deviations from Mean |
-1 |
-0.5 |
0 |
0.5 |
1.5 |
|
|
F(z) |
0.159 |
0.309 |
0.5 |
0.691 |
0.933 |
1 |
|
Expected n in that bin |
7.95 |
7.5 |
9.55 |
9.55 |
16.15 |
3.35 |
![]()
From the last row of this
table and the number of data values counted in each bin, the Chi-Squared
statistic is calculated as:
![]()

The probability depends on
the number of degrees of freedom. In
this case the number of degrees of freedom is the number of bins minus 1. It is one less than the number of bins
because once we know the number of data points in 5 of the bins, we know the
number in the final bin because we know the total number of points.
Table 8 shows probability values for Chi-Squared with 3, 4, 5 and 6 degrees of freedom:

![]()
Because the ![]() value is smaller than
11.07, the p value is greater than 0.05 and hence the null hypothesis, that the
two distributions are equal, cannot be rejected. We thus accept that the data could have come
from the proposed Gaussian distribution.
value is smaller than
11.07, the p value is greater than 0.05 and hence the null hypothesis, that the
two distributions are equal, cannot be rejected. We thus accept that the data could have come
from the proposed Gaussian distribution.
One is suspicious that the
distribution is not correct when the p value is low, but one can also be
concerned if the p value is too high.
Recall that p value indicates the probability of obtaining the data given
the underlying probability distribution.
It is unlikely to obtain data that are far from the distribution, but it
is also unlikely to obtain data that match the distribution highly well. Thus, if the ![]() value had been less
than 1.15, there would have been concern that the fit to the data was “too
good,” perhaps indicating that the data
had been faked.
value had been less
than 1.15, there would have been concern that the fit to the data was “too
good,” perhaps indicating that the data
had been faked.
If the problem statement had
not provided the mean and standard deviation these parameters could have been
estimated by calculating the mean and standard deviation of the data set. Since the two parameters would have been
estimated from the data, the number of degrees of freedom would have been
reduced by 2.
The student may be
interested to find that the data for this exercise were generated by
transforming uniform random variables to Gaussian random variables via the Box
Muller procedure described below. Thus,
the data truly were generated from the proposed underlying Gaussian
distribution.
![]() Exercise 4:
Use a Chi-Squared test on the data set in Table 6 to determine whether it is
consistent with a uniform
distribution.
Exercise 4:
Use a Chi-Squared test on the data set in Table 6 to determine whether it is
consistent with a uniform
distribution.
Expected Value and Mean
The expected value of a
random variable is defined as the first moment of its distribution. Specifically,
![]()
One should notice that the
expected value of a Gaussian distribution is located at the peak of the
distribution and is equivalent to the distribution’s “mean.” Often the terms “mean” and expected value are
used interchangeably. One may also speak
of a “sample mean,” which is the average of a number of random variables taken
from a distribution. For example, the
average of the data in Table 6 is 0.79 even though they are generated from a
distribution with a mean of 1.
Typically, if one is able to obtain an infinite number of data points
from the distribution, one will find that the mean of the data approaches the
expected value. This behavior does not
always hold, but it is an intuitive result and when it does hold, the random
variable is said to be ergodic.
Variance in terms of Expected Value
The variance of a random
variable is defined to be:
![]() .
.
One can verify that this definition for expected value provides a value of s that is equal to the parameter s in the definition of the Gaussian distribution.
F-Test
The F-test is used to
compare variances. One may use it to
either determine whether two data sets come from the same distribution or
whether a single data set matches a known underlying distribution. The F statistic is:
![]() ,
,
where ![]() is the standard
deviation calculated from one data set and
is the standard
deviation calculated from one data set and ![]() is the standard
deviation calculated from the other data set.
is the standard
deviation calculated from the other data set.
![]()

Example 3: A physician has both of his two new interns measure
the pressure drop in an arterial segment of a patient. He notices that the standard deviation of the
first intern’s data is 0.93 and that the standard deviation of the second
intern’s data is 1.32. Do the data
support the hypothesis that resident 1 is able to take data with less scatter
than resident 2?
 Solution:
The output from Excel is shown in the table below. There are 8 degrees of freedom for data set 1
and 7 for data set 2. In this case, the
degrees of freedom is the number of points minus 1. The F statistic is 0.490, and the probability
of obtaining this if the two distributions are identical is 0.17. Therefore, the null hypothesis cannot be
rejected and we cannot say that one intern is better than the other at making
this measurement.
Solution:
The output from Excel is shown in the table below. There are 8 degrees of freedom for data set 1
and 7 for data set 2. In this case, the
degrees of freedom is the number of points minus 1. The F statistic is 0.490, and the probability
of obtaining this if the two distributions are identical is 0.17. Therefore, the null hypothesis cannot be
rejected and we cannot say that one intern is better than the other at making
this measurement.
In the old fashioned way of
doing this test, one would look up the p-values in tables. The tables were typically written for F
values greater than 1, which meant that one would have to use the data set with
the larger variance as data set 1 (to obtain ![]() ).
).
![]()
Pearson’s Correlation Coefficient
The student is probably
familiar with the r value from a least squares fit. The r value measures how will the data points
fit the given line, but it does not directly state how likely it is that the
line has significance. If there are only
2 data points, the r value must be 1, regardless of how valid the data
are. However, if there are 100 points
and each point fits the line perfectly, then one can state that the least
squares fit is probably a good model for the underlying data. The Pearson’s correlation coefficient takes
into account the number of data points used in the fit and provides the
probability of obtaining the given set of if there is no correlation between
the two variables in the underlying physics of the problem.
![]()
 Example 4:
John Q. Researcher proposes that a person’s blood pressure is linearly
proportional to the person’s car’s gas mileage.
He surveys 10 people and collects the data to the right. Is this survey consistent with the hypothesis
within the p < 0.01 range?
Example 4:
John Q. Researcher proposes that a person’s blood pressure is linearly
proportional to the person’s car’s gas mileage.
He surveys 10 people and collects the data to the right. Is this survey consistent with the hypothesis
within the p < 0.01 range?
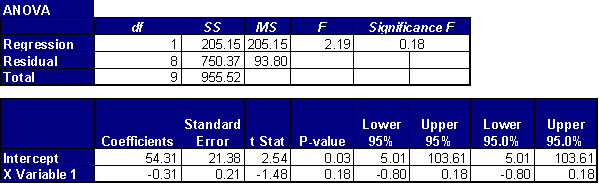
Solution: The easy way to do this is to input the data
values into Excel and perform a linear regression. Select “Tools | Data Analysis” and then click
on “linear regression.” (If the Data
Analysis menu does not appear see the Help menu under “regression” for
instructions on how to get it to appear).
Fill in the requested data (cells for y-range, cells, for x-range, and
cells for output) and hit “OK.” The
output should look like the data in the tables below (although not quite as
pretty):

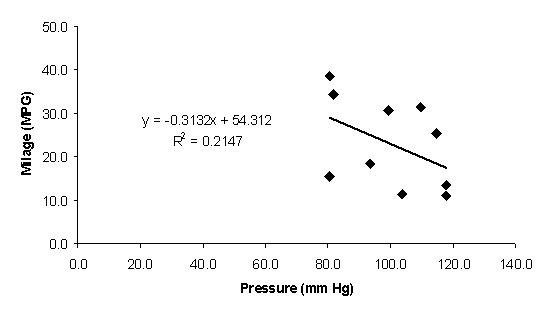
The relevant statistic here is the P-value for “X Variable 1” in the 3rd table. In this case the value is 0.18, which is much larger than 0.01, so the null hypothesis cannot be rejected, and it appears that the fit is not good.
The data and the least
squares fit appear in the figure below.
At first glance it may appear that there is some trend to the data, but
the statistical test contradicts this perception. As confirmation that there is no underlying
pattern, the data were generated from the “rand” function of Excel. The example
illustrates the danger of relying on one’s perception in making conclusions
from this kind of data.
![]()
Transforming Distributions
It is possible to transform
random variables that have one distribution to random numbers with another
distribution. For example, if you wanted
to generate Gaussian random variables with the rand() function, you could use
the Box-Muller procedure. In this
method, two random numbers, x1 and x2, that are uniform
between 0 and 1 are generated. The
Gaussian numbers y1 and y2 are then generated as follows:
![]()
![]()
These will have a mean of zero and a standard deviation of 1.
Example 5:
Show how you could generate 6 normal random numbers in Excel.
Solution:
|
|
A |
B |
C |
|
1 |
=rand() |
=sqrt(-2.*ln(A1)) * cos(2*pi()*A2) |
|
|
2 |
=rand() |
=sqrt(-2.*ln(A1)) *
sin(2*pi()*A2) |
|
|
3 |
=rand() |
=sqrt(-2.*ln(A3)) * cos(2*pi()*A4) |
|
|
4 |
=rand() |
=sqrt(-2.*ln(A3)) *
sin(2*pi()*A4) |
|
|
5 |
=rand() |
=sqrt(-2.*ln(A5)) * cos(2*pi()*A6) |
|
|
6 |
=rand() |
=sqrt(-2.*ln(A5)) *
sin(2*pi()*A6) |
|
|
7 |
|
|
|
|
8 |
|
|
|
![]() Column B will
have 6 independent normal random with mean 0 and standard deviation of 1 numbers
in it.
Column B will
have 6 independent normal random with mean 0 and standard deviation of 1 numbers
in it.
Example 6: How
would you generate normal random numbers that had a mean of 21 and a standard
deviation of 5?
|
|
A |
B |
C |
|
1 |
=rand() |
=sqrt(-2.*ln(A1)) * cos(2*pi()*A2) |
=B1*5 + 21 |
|
2 |
=rand() |
=sqrt(-2.*ln(A1)) *
sin(2*pi()*A2) |
=B2*5 + 21 |
|
3 |
=rand() |
=sqrt(-2.*ln(A3)) * cos(2*pi()*A4) |
=B3*5 + 21 |
|
4 |
=rand() |
=sqrt(-2.*ln(A3)) *
sin(2*pi()*A4) |
=B4*5 + 21 |
|
5 |
=rand() |
=sqrt(-2.*ln(A5)) * cos(2*pi()*A6) |
=B5*5 + 21 |
|
6 |
=rand() |
=sqrt(-2.*ln(A5)) *
sin(2*pi()*A6) |
=B6*5 + 21 |
|
7 |
|
|
|
|
8 |
|
|
|
Solution: One
needs to multiply the zero-mean normal random variables by the standard
deviation and add the mean.
Exercise 5: Use
Excel to generate 40 sets of pairs of 10 random numbers having a uniform
distribution between 0 and 1. Because
these two have the same distribution, the T-test should show that there is no
statistically significant difference in their means. Perform a 2-sample, equal variance,
one-tailed T-test on each set and examine the p-values. Are any of them significant to the p <
0.05 level? Note, you can use the
ttest() function in Excel. For example,
if data set 1 is in a1:a10 and data set 2 is in b1:b10, you can write
“=ttest(A1:A10, B1:B10, 1, 2)” in cell C1 to get the 1 tailed, equal variance
test. If the next set is in columns
A11:A20 and B11:B20, you then need only copy cell C1 to cell C11.
![]()
Exercise 6: Use
the Box-Muller method to transform the pairs of numbers generated in Exercise 5
to Gaussian numbers. Check that the
distributions of the normal and Gaussian random numbers are reasonable by doing
a historgram (found under “Tools | Data Analysis” in Excel) on the data and
plotting the results. On the same plot
show the probability density of the corresponding data set. Do the distributions look reasonable?
![]() Exercise 7: Now
repeat the T-test on each set. Do any of
the T-tests show significance to the 0.05 level? Note the meaning of the p < 0.05
statistic: “This is the probability that these data could be generated by two
distributions that are exactly identical.”
Is the result you obtained consistent with this statement? Why or why not?
Exercise 7: Now
repeat the T-test on each set. Do any of
the T-tests show significance to the 0.05 level? Note the meaning of the p < 0.05
statistic: “This is the probability that these data could be generated by two
distributions that are exactly identical.”
Is the result you obtained consistent with this statement? Why or why not?
One- and Two-Tailed Tests
The null hypothesis is
typically a statement that two entities are equal. For example, means are proposed to be equal
for the T-test, variances are assumed to be equal for the F-Test, and
probability distributions are assumed to be equal for the Chi
Squared-test. To use a statistical test,
the “alternative hypothesis” must be specified.
For the T-test, for example, one can propose that the mean for variable
1 is greater than that for variable 2, or one can propose that the two means
are different. If one proposes that
variable 1 is greater than variable 2, one is being more restrictive (taking a
greater risk of being wrong) than if one proposes simply that the two variables
are different. The reward for taking the
extra risk is that one need only examine one tail of the T-test
distribution. If the alternate
hypothesis is simply that the two means are different, both tails of the T-test
must be examined.
Use a 1 tailed T-test if your alternative hypothesis is that one of the variables is greater than the other. Use a 2 tailed test if your alternative hypothesis is that the two variables are different. How do you determine which alternative hypothesis to make? It depends on the circumstances.
![]()
Example 4: A coin is tossed 7 times and comes up “heads” every
time. Is the coin biased towards heads
at the p < 0.01 level?
Solution: The probability of a coin toss yielding N heads in a row is ![]() . Therefore, the
probability of having 7 heads in a row is 1/128, or 0.00781, which is less than
0.01. Therefore it is concluded that the
coin is biased toward heads at the 0.01 level.
. Therefore, the
probability of having 7 heads in a row is 1/128, or 0.00781, which is less than
0.01. Therefore it is concluded that the
coin is biased toward heads at the 0.01 level.
Example 5: A coin is tossed 7 times and comes up “heads” every
time. Is the coin biased at the p <
0.01 level?
Solution: In asking if the coin is biased, one must
look at all outcomes that would make one conclude that the coin was
biased. One of these outcomes is 7 heads
in a row, but 7 tails in a row would provide an equivalent conclusion. Therefore, one must add the probabilities in
both tails of the distribution. The
result is thus twice 0.00781, or 0.0156, which is greater than 0.01. Therefore it cannot be concluded that the
coin is biased at the 0.01 level.
![]()
The two examples above form
a paradox. How is it possible to
conclude that the coin is biased in a certain direction and yet not be able to
conclude that it is biased. After all,
if the coin is biased in a particular direction, it must be biased, right?
The resolution of the
paradox lies in how the alternative hypothesis is formed. If one proposes that the coin tosses will
generate 7 heads in a row and then obtains 7 heads in a row, the initial
prediction is correct and all onlookers are impressed. If, on the other hand, he makes the same prediction
and obtains 7 tails in a row, the initial prediction is incorrect and nobody is
impressed. On the contrary, the process
may generate gales of laughter from the audience. However, if one proposes that the coin will
generate the same side 7 times in a row, and it comes up with either 7 heads or
7 tails, everyone is still impressed. It
must be remembered that the experimenter is not allowed to look at the data
before he/she formulates the alternative hypothesis. Thus, one is not simultaneously concluding
that “the coin is almost certainly biased toward heads but is not certain to be
biased.” Rather, one is measuring how
closely the data match the original prediction, which was either that the coin
was biased towards heads or that the
coin was biased in one direction or the other.
![]() Exercise 8:
If you initially proposed that the means of Event 1 and Event 2 below were
different, what would you conclude at the p < 0.01 level?
Exercise 8:
If you initially proposed that the means of Event 1 and Event 2 below were
different, what would you conclude at the p < 0.01 level?
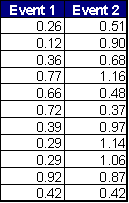
![]() Exercise 9:
For the same set of data, what would you have concluded if you had initially
proposed that the mean of data set 1 was different from the mean of data set 2?
Exercise 9:
For the same set of data, what would you have concluded if you had initially
proposed that the mean of data set 1 was different from the mean of data set 2?
The Paired T-Test
When comparing means of data, there are often relationships between the individual points in each data set. For example, assume that you wish to determine whether, on average, the left kidney weighs less than the right kidney. It does not make sense to pool all left kidneys in one group and all right kidneys in the other. A better approach is to compare left and right kidneys from each individual. Consider the following data set:
|
Patient |
Left
Kidney Weight |
Right
Kidney Weight |
|
Abrams |
6.3 |
6.5 |
|
Bradley |
5.7 |
5.9 |
|
Dillard |
7.1 |
7.5 |
|
Prudhomme |
6.2 |
6.3 |
|
|
5.1 |
5.7 |
|
Saunders |
4.8 |
5.1 |
|
|
6.5 |
6.8 |
In looking at the mean and
standard deviation of each column, it is not clear that there is a significant
difference. The p value of 0.247
indicates that there is no significant difference. However, a second look at the data shows that
each value for the left kidney is smaller than the corresponding value for the
right kidney. A possible explanation is
that each person has a different weight, and the kidney’s weight may scale to
the patient’s weight. The paired T-test
takes into account the possibility that each pair of data in the data set may
have some innate connection. In these
cases you can use the paired t-test in excel.
There are obvious cases where the paired t-test would not be of value,
however. For example, if the left and
right kidneys did not come from the same patient there would be no grounds for
pairing. One who designs experiments
should be aware of cases where this kind of pairing can be taken advantage of.
![]()
Exercise 10: Perform a paired T-test on the data in the
table above. Do the data support the
hypothesis that the left kidney weighs less than the right kidney to the p <
0.01 level?
Conclusion
There are several
statistical tests available to test certain hypotheses. Which test is used depends on the statistic
of interest (mean, standard deviation, probability distribution, etc.), the
null hypothesis, and the alternative hypothesis. A good book on statistics is a valuable tool
for anyone who needs to design experiments or interpret experimental data. Generally, for a given test it will be
necessary to calculate a statistic from the data (T statistic, F statistic,
Chi-Squared statistic, etc.) and determine a probability value based on the
number of degrees of freedom. A wide
variety of software is available to perform statistical tests. Although Excel is not specifically designed
for statistical tests, it has several of them build in and is therefore
convenient for some of the more common statistical tests.
To be valid, a statistical
test must be proposed before the experiment is performed. If an experimenter looks at the data before
forming a hypothesis, the validity of the test is contaminated. For example, one cannot first notice that the
mean of one set of data is larger than the mean of the other and then perform
the T-test. If one notices such a trend,
it is necessary to collect a new set of data to be completely unbiased.
Senior Design
Senior Laboratory
Research Experiences for Undergraduates
in Micro/Nano Engineering
Steven A. Jones
Last Updated February 26, 2005